تحول در تجارت بصری با مدلهای بینایی رایانه ای
تحول در تجارت بصری با مدلهای بینایی رایانه ای

شرکت هایی مانند eBay و آمازون میلیون ها تصویر از محصولات را ذخیره می کنند. هر تصویر حاوی اطلاعات زیادی است که می تواند برای کمک به مصرف کنندگان در یافتن محصول مناسب یا تبلیغ محصولات مشابه مورد استفاده قرار گیرد. با در دسترس بودن و اثربخشی مدل های بینایی رایانه ، یعنی شبکه های عصبی پیچیده ، حجم بالای اطلاعات موجود در تصاویر در حال حاضر بسیار در دسترس است. در ODSC West در سال 2018 ، رابینسون پیراموتو از Ebay تکنیک های کلیدی را برای هدایت چالش ها در ایجاد تحول در تجارت بصری با مدل های بینایی رایانه ای ارائه کرد.
[مقاله مرتبط: ترکیب میلیون ها محصول در یک بازار با استفاده از دید کامپیوتر و NLP] < /p>
رابینسون پیراموتو در مورد سه راه برای استفاده از یادگیری عمیق برای ابداع تجارت بصری ، از جمله پیش بینی جنبه ، پیش بینی دسته برگ و شناسایی امضا برای رتبه بندی بصری بحث کرد. هر رویکرد از یک شبکه عصبی مشترک استفاده می کند ، اما لایه نهایی برای هر یک از وظایف خاص طراحی شده است.

رویکرد کلی
روش مدل سازی برای پیش بینی تصاویر داده شده از محصولات ، نیاز به آموزش تصاویر برچسب زده شده دارد. رابینسون آموزش مدل یادگیری عمیق را بر روی تصاویر با زمینه ساده در مراحل اولیه توصیه می کند تا به مدل اجازه دهد از نمونه های آسان یاد بگیرد. علاوه بر این ، او بر مفید بودن تصاویر با زوایای گوناگون که نمایانگر غنی تری از ویژگی های عکس هستند ، تأکید کرد. علاوه بر این ، نمونه برداری از تصاویر از انواع مارک ها ، فروشندگان ، شرایط و انواع کلیدی است تا بتوان مدل را به خوبی در تصاویر وحشی تعمیم داد.
 https://bit.ly/300txgY
https://bit.ly/300txgYجستجوی بصری
در تجارت بصری ، به نفع بتواند محصولاتی را به مصرف کننده توصیه کند که مشابه محصولات قبلی است. برای این منظور ، لازم است محصولات مشابه را با اندازه شباهت گروه بندی کنید. رابینسون پیراموتو به جای روشهای یادگیری بدون نظارت مانند PCA یا K-Means Clustering ، استفاده از یک روش نیمه تحت نظارت را توصیه می کند. این مستلزم آموزش شبکه عصبی بر روی گروهی از کلاس ها است (Ebay از 16000 کلاس استفاده می کند) ، سپس تصاویر بدون برچسب را در شبکه قرار می دهد. در نهایت ، باید کلاسهایی را انتخاب کنید که تصویر مورد نظر بیشتر شبیه آنها است. معیارهای انتخاب کلاسهای مشابه معمولاً براساس مقادیر فعالسازی softmax است که احتمالات پیش بینی شده برای مدل برای هر کلاس را نشان می دهد. تیم رابینسون تعیین کردند که با تعیین یک آستانه برای احتمالات تجمعی ، بر اساس احتمال نرم حداکثر حداکثر عملکرد مطلوب نسبت به آستانه ها به دست آمد. در مثال زیر ، با آستانه تجمعی 0.9 ، مقوله های C1-C3 به طور مناسب شبیه تصویر مورد نظر شناخته می شوند.

پیش بینی جنبه ای
اغلب ویژگی های کلیدی در توضیحات یک مورد وجود ندارد و نیاز به راهی برای پر کردن سریع ویژگی های از دست رفته است به با مهندسی مجدد آخرین لایه کاملاً متصل برای یک شبکه عصبی پیچشی ، می توانید محصولات را بر اساس الگو ، مارک یا مد ، که در زیر نشان داده شده است ، جدا کنید.

ویژگیها باید زودتر از موعد مشخص شوند که با ویژگیهای کلیدی انتخاب مشتری مطابقت دارد و از طریق تصاویر قابل شناسایی است. به عنوان مثال ، نام تجاری را می توان با یادگیری عمیق شناسایی کرد ، اما چیزی مانند اندازه نمی تواند. ویژگی بیشتر با توجه به توصیفات محصول می تواند به رابط وب فرد اجازه دهد تا محصولات را با دقت بیشتری جستجو کند.
خوب تکراریتنظیم
رابینسون به تکنیکی جالب برای تنظیم دقیق روند آموزش شبکه های عصبی اشاره کرد که شامل تغییر میزان یادگیری از طریق یک فرآیند آموزش تکراری است. ابتدا ، یک شبکه را با نرخ یادگیری اولیه 01/0 تا زمان همگرایی مدل (یعنی فلاتهای صحت اعتبار سنجی) آموزش می دهد. خط تیره خاکستری در پایین شکل زیر نشان دهنده اولین تکرار تمرین است. سپس همان مدل با نرخ یادگیری بالاتر بازآموزی می شود که در ابتدا باعث کاهش دقت می شود ، اما با نرخ دقت بالاتری نسبت به مدل قبلی همگرا می شود. این روند تا زمانی ادامه می یابد که افزایش میزان یادگیری دیگر منجر به بهبود نشود.
 < /img>
< /img> [مقاله مرتبط: 4 مرحله برای شروع یادگیری ماشین با دید رایانه]
نکات کلیدی:
پست اصلی اینجا.
مقالات علم داده بیشتر را در OpenDataScience.com بخوانید ، از جمله آموزش ها و راهنماهای مبتدی تا پیشرفته! در خبرنامه هفتگی ما اینجا مشترک شوید و آخرین اخبار را هر پنجشنبه دریافت کنید.
بینایی رایانه ای در تسلا
بینایی رایانه ای در تسلا
وقتی به دنیای بینایی رایانه نگاه می کنیم ، می توانیم یک فاصله واقعی بین دوره های واقعیت و آنلاین مشاهده کنید.
به عنوان مثال ، شما ممکن است در یک دوره آنلاین نحوه اجرای یک شبکه YOLO را بیاموزید ، اما یک مورد استفاده در دنیای واقعی ممکن است 7 شبکه YOLO را در GPU های توزیع شده درخواست کند. و معماری HydraNet این چه عجایبی است؟ ما همه اینها را در Coursera نیاموختیم!
بنابراین امروز ، تصمیم گرفتم ویدیویی را از Andrej Karpathy ، AI Lead در تسلا جدا کنم و آنچه را که در داخل نرم افزار تسلا اتفاق می افتد برای شما توضیح دهم. پیوند ویدیو را در پایان این مقاله به اشتراک می گذارم.
امیدوارم متوجه شوید که هیچ چیز را نمی توانید درک کنید ، حداقل از یک مفهوم سطح بالا. < /p> 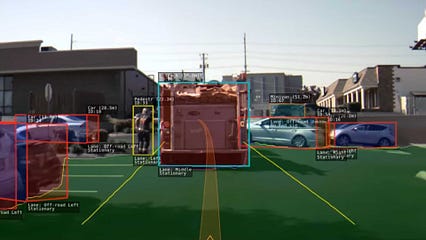
عمیقاً در زیر فرو می رویم:
به طور خاص ، ما به یکی از نگرانی های مهم تسلا می پردازیم: 50 کار باید روی رایانه انجام شود ، به طور همزمان ، در رایانه ای که فضای زیادی را اشغال نمی کند.
 رایانه FSD
رایانه FSD پس بیایید به آن برسیم!
قبل از آن
1. وظایف
به گفته ایلان ماسک ، از ابتدای ژوئیه (2020) ، تسلا به خودروهای کاملاً خودران نزدیک است-که به عنوان خودمختاری سطح 5 نیز شناخته می شود. چه واقعیت داشته باشد چه نباشد ، یک چیز بیش از پیش روشن می شود: تسلا آماده است تا قبل از دیگران به خودمختاری کامل برسد. هنگامی که آنها این کار را انجام می دهند ، بقیه احتمالاً به سرعت دنبال می شوند.
یک وسیله نقلیه تسلا چه کار می کند؟
عملکرد اصلی هر وسیله نقلیه خودران ، از جمله کارهایی که در تسلا انجام می شود این است که در خط صحیح بمانید ، سپس مسیر را تغییر دهید تا مسیر درست را دنبال کنید.
بدیهی است که وظایفی مانند تشخیص موانع بخش بزرگی از پشته است. و ویژگی های دیگر مانند Smart Summon به خودرو اجازه می دهد تا راننده را در یک پارکینگ پیدا کند. این وظایف اضافی ، در میان سایر وظایف ، به خط اصلی و مسیر اصلی حرکت می کند تا به سمت هدف بلند مدت حرکت کند: قابلیت های کامل خودران.
 تسلا باید تمام این وظایف را انجام دهد
تسلا باید تمام این وظایف را انجام دهد 2. حسگرها
تسلا از 8 دوربین برای عملکرد استفاده می کند. با این کار ، آنها می توانند تمام مناطق اطراف وسیله نقلیه را پوشش دهند تا نقطه کوری وجود نداشته باشد.
 نمای از 8 دوربین
نمای از 8 دوربین 8 دوربینبا RADAR های اضافی ترکیب می شوند تا بتوانند موانع را به طور م locateثر شناسایی و آنها را شناسایی کنند. RADAR ها حسگرهای مکمل بسیار خوبی هستند زیرا می توانند سرعتها را مستقیماً تخمین بزنند. می توانید در مقاله RADAR من بیشتر بیاموزید.
این تصاویر دوربین چگونه پردازش می شوند؟ استفاده از شبکه های عصبی.
3. شبکه های عصبی
بین وسایل نقلیه ، خطوط پیاده رو ، حاشیه جاده ها ، گذرگاه ها و سایر متغیرهای محیطی خاص ، تسلا کارهای زیادی برای انجام دادن دارد. در حقیقت ، آنها باید حداقل 50 شبکه عصبی را به طور همزمان اجرا کنند تا بتواند کار کند. این امر در رایانه های معمولی امکان پذیر نیست.
 شبکه عصبی تسلا < /img>
شبکه عصبی تسلا < /img> شبکه های عصبی با استفاده از PyTorch ، یک چارچوب یادگیری عمیق که ممکن است با آن آشنا باشید ، آموزش می بینند.
چیز دیگری که تسلا استفاده می کند نمای چشم پرنده است
گاهی اوقات نتایج یک شبکه عصبی باید به صورت سه بعدی تفسیر شود. نمای چشم پرنده می تواند به تخمین فاصله ها کمک کند و درک بسیار بهتر و واقعی تری از جهان ارائه دهد.
 احضار هوشمند در تسلا با استفاده از نمای چشم پرنده
احضار هوشمند در تسلا با استفاده از نمای چشم پرنده برخی از کارها بر روی چندین دوربین اجرا می شوند. به عنوان مثال ، برآورد عمق چیزی است که ما عموما در دوربین های استریو انجام می دهیم. داشتن 2 دوربین به تخمین بهتر فاصله ها کمک می کند. تسلا این کار را با استفاده از شبکه های عصبی با رگرسیون در عمق انجام می دهد.
 برآورد عمق از 2 دوربین
برآورد عمق از 2 دوربین تسلا همچنین وظایف مکرر مانند برآورد چیدمان جاده دارد. این ایده مشابه است: چندین شبکه عصبی به طور جداگانه اجرا می شوند و یک شبکه عصبی دیگر در حال ایجاد اتصال است.

به صورت اختیاری ، این شبکه عصبی می تواند مکرر باشد تا زمان را در بر گیرد.
به این معنی است که برای هر پاس رو به جلو ، 4096 تصویر پردازش می شود. من در مورد شما اطلاعی ندارم ، اما MacBook Pro من هرگز نمی تواند از این پشتیبانی کند. در واقع ، GPU نمی تواند این کار را انجام دهد - نهحتی 2 GPU!
برای حل این مشکل ، تسلا روی معماری HydraNet شرط بندی می کند. هر دوربینی از طریق یک شبکه عصبی واحد پردازش می شود. سپس همه چیز در شبکه عصبی میانی ترکیب می شود. نکته شگفت انگیز این است که هر کاری تنها به چند قسمت از این شبکه غول پیکر نیاز دارد.
به عنوان مثال ، تشخیص شیء فقط به دوربین جلو ، ستون فقرات جلو و دوربین دوم نیاز دارد. همه چیز یکسان پردازش نمی شود.
 8 شبکه عصبی اصلی مورد استفاده تسلا
8 شبکه عصبی اصلی مورد استفاده تسلا 4. آموزش
آموزش شبکه با استفاده از PyTorch انجام می شود. چندین کار مورد نیاز است و آموزش بر روی 48 سر شبکه عصبی می تواند زمان زیادی را صرف کند. در حقیقت ، آموزش برای تکمیل به 70،000 ساعت GPU نیاز دارد. تقریباً 8 سال است.
تسلا در حال تغییر حالت آموزش از "رفت و برگشت" به "استخر کارگران" است. در اینجا ایده وجود دارد: در سمت چپ - گزینه طولانی و غیرممکن. در وسط و راست ، گزینه های جایگزین مورد استفاده آنها.

5. بررسی کامل پشته
امیدوارم اکنون ایده روشنی از نحوه کار در آنجا داشته باشید. درک آن غیرممکن نیست ، اما قطعاً متفاوت از چیزی است که ممکن است به آن عادت کرده باشیم. چرا؟ از آنجا که این شامل مشکلات بسیار پیچیده ای در دنیای واقعی است.
علاوه بر این ، تسلا باید به طور مداوم نرم افزار خود را بهبود بخشد. آنها باید داده های کاربران را جمع آوری کرده و از آنها استفاده کنند. از این گذشته ، آنها هزاران وسیله نقلیه دارند که در آنجا رانندگی می کنند ، احمقانه خواهد بود که از داده های آنها برای بهبود مدل خود استفاده نکنند. هر داده ای جمع آوری ، برچسب گذاری و برای آموزش استفاده می شود. شبیه فرایندی به نام یادگیری فعال (در این مورد در اینجا اطلاعات بیشتری کسب کنید).
 پشته کامل تسلا
پشته کامل تسلا بیایید پشته را از پایین به بالا تعریف کنیم.
⏩ در اینجا ویدئویی است که همه چیز را شرح می دهد. فقط تصاویری را که به شما نشان دادم نوشتم و جمع آوری کردم.
ممکن است کمی از همه چیز که توضیح دادم غرق شده باشید. بسیار پیشرفته تر از آن چیزی است که اکثر دوره ها آموزش می دهند ، و طبیعی است. با این حال ، امروزه شرکت ها اینگونه عمل می کنند. آن استبه ندرت می توان شرکتی را مشاهده کرد که از دسته های از پیش ساخته شده از لایه های متحرک بدون تغییر استفاده کند.
در اینجا خلاصه ای از همه مواردی است که ما در مورد آن بحث کردیم:
هدف تسلا این است که اولین شرکتی باشد که به خودمختاری کامل دست یافته است. امروزه آنها با ارزش ترین شرکت خودروسازی در کل جهان هستند و قصد توقف در آنجا را ندارند. آنها با چالش های جالبی روبرو هستند که ما در هنگام یادگیری هوش مصنوعی و یادگیری عمیق از راحتی خانه های خود با آنها روبرو نیستیم.
تبصره ویرایشگر: ضربان قلب یک نشریه و انجمن آنلاین مبتنی بر مشارکت است که به کاوش در تقاطع نوظهور توسعه برنامه تلفن همراه و یادگیری ماشین اختصاص داده شده است. ما متعهد هستیم که از توسعه دهندگان و مهندسان از هر قشری حمایت و الهام بگیریم.
مستقل از نظر ویرایش ، Heartbeat توسط Fritz AI ، پلت فرم یادگیری ماشینی که به توسعه دهندگان کمک می کند تا دستگاه ها را ببینند ، بشنوند ، حمایت و منتشر می شود. حس کنید و فکر کنید ما به مشارکت کنندگان خود پرداخت می کنیم و تبلیغات نمی فروشیم.
اگر می خواهید مشارکت داشته باشید ، به تماس ما برای مشارکت کنندگان سر بزنید. همچنین می توانید برای دریافت خبرنامه های هفتگی ما (هفته نامه یادگیری عمیق و خبرنامه هوش مصنوعی Fritz) ثبت نام کنید ، در Slack به ما بپیوندید و Fritz AI را در توییتر دنبال کنید تا آخرین یادگیری ماشین تلفن همراه را مشاهده کنید.