توجه به کاغذ در مقابل توجه به استفاده از رایانه
توجه به کاغذ در مقابل توجه به استفاده از رایانه
و نحوه یادداشت برداری روی کاغذ برای حفظ اطلاعات بسیار بهتر است.
 عکس توسط کلی سیکما در Unsplash
عکس توسط کلی سیکما در Unsplash حفظ اطلاعات در حافظه بلند مدت ما یکی از مهمترین کارهایی است که می توانیم برای یادگیرندگان مادام العمر انجام دهیم.
یادگیری چیزی در کوتاه مدت چیست؟
برنامه های بینایی رایانه ای در اتومبیل های خودران
برنامه های بینایی رایانه ای در اتومبیل های خودران

قبل از شروع ، از شما دعوت می کنم به لیست ارسال نامه های خودگردان بپیوندید و هر روز یاد بگیرید در مورد اتومبیل های خودران ، دید رایانه ای و هوش مصنوعی.
مقالات پرطرفدار هوش مصنوعی:
AI ... و وسیله نقلیه خودکار رفت
این اولین مقاله را هنگام یادگیری اتومبیل های خودران با Udacity به عنوان بخشی از نانو درجه آنها نوشتم. برنامه.
برای این مشکلات ، من به ترتیب از دید رایانه رایانه ای ، یادگیری ماشین و یادگیری عمیق استفاده کردم.
 چشم انداز رایانه ای برای تشخیص خطوط خط
چشم انداز رایانه ای برای تشخیص خطوط خط از رایانه رایانه ای سنتی برای یافتن خطوط خط در جاده ، حتی خطوط منحنی استفاده شد. این رشته همه چیز در مورد استفاده از کتابخانه OpenCV و مطالعه رنگ پیکسل ها برای به دست آوردن شکل مناسب است.
 یادگیری ماشین برای تشخیص وسیله نقلیه >
یادگیری ماشین برای تشخیص وسیله نقلیه > یادگیری ماشین به عنوان طبقه بندی کننده با پنجره کشویی برای یافتن اتومبیل و موانع استفاده شد. طبقه بندی SVM اغلب دارای دو کلاس بود: خودرو و خودرو. زاویه فرمان با استفاده از یادگیری تقلیدی و روش یادگیری عمیق پایان به پایان تعیین شد. من آموختم. استحکام را می توان با استفاده از فیلتر کالمن تصحیح کرد ، اما عملکرد چیز دیگری است.
یادگیری ماشین نتایج بدی برای تشخیص موانع ، به ویژه هنگام تشخیص بیش از یک کلاس ، داشت. تکنیک پنجره کشویی نیز در مقایسه با الگوریتم های اخیر بسیار کند است. یادگیری تقویتی نیز امیدوار کننده تر به نظر می رسد اما هنوز در تحقیقات تجربی است.
رویکردهای مدرن
بینایی رایانه ، یادگیری ماشین و یادگیری عمیق به طور کلی راه حل های خوبی برای مشکلات ادراکی هستند.
< p> اخیراً ، یادگیری عمیق با استفاده از شبکه های عصبی کانولوشن از هر تکنیک دیگری برای تشخیص خط و موانع پیشی گرفته است. آنقدر که حتی ارزش امتحان چیز دیگری را ندارد.مقاله قبلی من از شبکه های عصبی متحد (CNNs) به عنوان روشی جدید برای حل مشکلات بینایی رایانه یاد کرد.
< p> CNN ها معماری خاصی از شبکه های عصبی هستند که می توانند با استفاده از Convolutions شکل های خاصی (مانند اتومبیل ، عابر پیاده و ...) را بیاموزند. از داده های بیشتری نسبت به الگوریتم های یادگیری ماشین استفاده می کند ، و آموزش سخت تر است ، اما نتایج بسیار بهتر است.معماری یادگیری عمیق امروزه می تواند برای اهداف خاصی مانندتشخیص جعبه محدوده یا رگرسیون ضریب خط. بر خلاف "روش طبقه بندی" ، نیازی به استفاده از پنجره کشویی یا هیستوگرام برای خروجی نتیجه مورد نظر نیست. شبکه های عصبی را می توان طوری تنظیم کرد که هر چه می خواهیم تولید کنند.
تشخیص خودرو

هنگام تشخیص موانع ، نتیجه به طور کلی فراتر از خروج ساده خودرو یا عدم رانندگی است. ما به مختصات کادر محدود کننده (x1 ، y1 ، x2 ، y2) نیاز داریم که قبلاً با پنجره کشویی داشتیم. ما به اطمینان نمره (تا آستانه مقادیر اطمینان پایین) و کلاس (خودرو ، عابر پیاده ،…) که الگوریتم SVM بدست آورده ایم نیاز داریم. در انتهای شبکه عصبی.
لایه های متحرک برای یادگیری ویژگی های مستقل (اندازه ، رنگ ، شکل) در حالی که آخرین لایه ها در اینجا برای خروجی هستند. آنها یاد می گیرند که مختصات جعبه محدود کننده و سایر ویژگیهای مرتبطی را که ما به آنها نیاز داریم ، تولید کنند. همه در یک شبکه عصبی واحد انجام می شود.
 معماری CNN برای تشخیص موانع < /img>
معماری CNN برای تشخیص موانع < /img> تشخیص خطوط مسیر
برای تشخیص خطوط خط ، یادگیری عمیق را می توان دقیقاً به همان شیوه استفاده کرد.
نقش ایجاد ضرایب معادله خط خط است. خطوط خط را می توان با معادلات ضرایب درجه اول ، دوم یا سوم تقریب زد. معادله مرتبه اول به سادگی ax+b (یک خط مستقیم) است در حالی که ابعاد بالاتر اجازه ایجاد منحنی ها را می دهد.
 خطوط 1D در مقابل خط دو بعدی
خطوط 1D در مقابل خط دو بعدی در CNN ، لایه های کانولوشن ویژگی ها را می آموزند ، در حالی که آخرین لایه ها ضرایب خط (a ، b و ج).
این ممکن است ساده به نظر برسد: چند لایه پیچشی تنظیم کنید ، چند لایه متراکم تنظیم کنید و معماری خروجی را تنها با 3 نورون برای ضرایب a ، b و c تنظیم کنید.
< در واقع ، این راه سخت تر است. مجموعه داده ها همیشه ضرایب خطوط خط را ذکر نمی کنند و همچنین ممکن است بخواهیم نوع خط (خط کشی ، جامد ،…) و همچنین اینکه آیا خط متعلق به خط وسیله نقلیه ego است یا به یک خط مجاور تشخیص دهیم. ویژگیهای متعددی وجود دارد که ممکن است بخواهیم داشته باشیم و آموزش یک شبکه عصبی واحد بسیار دشوار و تعمیم آن دشوارتر است.یک روش رایج برای حل این مشکل استفاده از تقسیم بندی است. در تقسیم بندی ، هدف این است که به هر پیکسل یک تصویر کلاس داده شود.
 یک رنگ در هر کلاس
یک رنگ در هر کلاس در این رویکرد ، هر خط مربوط به یک کلاس (ego چپ ، ego راست ، ...) است و هدف شبکه عصبی ایجاد تصویری فقط با این رنگ ها است.
 نمونه تصویر خروجی
نمونه تصویر خروجی در این نوع معماری ، سیستم عصبی شبکه در دو قسمت کار می کند قسمت اول ویژگی ها را یاد می گیرد ، قسمت دوم خروجی را می آموزد. درست مانند تشخیص جعبه.
 معماری U-Netبرای تشخیص خطوط
معماری U-Netبرای تشخیص خطوط 
اگر خروجی یک تصویر سیاه ساده با رنگ ، استفاده از یادگیری ماشین و رگرسیون خطی (یا چندگانه) برای یافتن خطوط خط در نقاط رنگی بسیار ساده است. 10 برابر سریعتر در آزمایشاتم ، 5 رویکرد FPS برای رویکرد دید رایانه ای و حدود 50 FPS برای رویکرد یادگیری عمیق داشتم.
موارد دیگر برای یادگیری عمیق در اتومبیل های خودران-ردیابی
I اخیراً مقاله ای منتشر شد که بسیار مورد توجه قرار گرفت: چشم انداز رایانه ای برای ردیابی.
در این مقاله ، من به تکنیکی برای ردیابی موانع در طول زمان با استفاده از دوربین ، یادگیری عمیق و الگوریتم های هوش مصنوعی مانند کالمن اشاره می کنم. فیلترها و الگوریتم مجار.
در اینجا ، جعبه های محدود کننده مانند یک روش کلاسیک YOLO رنگ ها را از قاب 1 به قاب 2 تغییر نمی دهند. اتومبیل سمت راست دارای یک جعبه محدود مشکی در قاب 1 و در قاب 2 به دلیل ارتباط است. اشیاء همرنگ جعبه های رنگی یکسانی ندارند.
یادگیری این نتیجه برای شبکه های عصبی بسیار دشوار است. به همین دلیل است که ما از فیلترینگ بیزی و الگوریتم ارتباط استفاده می کنیم. در اینجا درک بهتری داشته باشید.
در این رویکرد ، Deep Learning برای محدود کردن تشخیص جعبه استفاده می شود و نتیجه بلافاصله به الگوریتم های دیگر منتقل می شود که تصمیم می گیرند آیا وسیله نقلیه قبلی مشابه است یا خیر. به برای تصمیم گیری ، ویژگی های متغیر نیز می توانند به عنوان مطابقت بستگی به ظاهر شیء داشته باشند. برای یادگیری عمیق در اتومبیل های خودران-جعبه های محدود کننده سه بعدی 
جعبه های محدود کننده بسیار عالی هستند تا بتوانیم موانع را بومی سازی کنیم. با این حال ، داشتن محلی سازی دو بعدی با مختصات پیکسل ممکن است چندان مفید نباشد. آنچه ترجیح داده می شود این است که موقعیت سه بعدی با x ، y ، z به طور مستقیم وجود داشته باشد.
به نظر می رسد که از مختصات پیکسل این امر بسیار دشوار است:
 جعبه های محدود کننده 2 بعدی در مقابل 3D (منبع)
جعبه های محدود کننده 2 بعدی در مقابل 3D (منبع) مقاله مربوط به روشی برای برآورد جعبه های محدود کننده سه بعدی بحث می کند با استفاده از یادگیری عمیق و هندسه.
 معماری شبکه عصبی برای برآورد سه بعدی
معماری شبکه عصبی برای برآورد سه بعدی در این رویکرد ، Deep Learning مجدداً برای یادگیری ویژگی (ابعاد ، زاویه ، اطمینان) استفاده می شود. سپس از هندسه برای ترجمه اطلاعات به جهان سه بعدی استفاده می شود.
تشخیص فضای آزاد
تشخیص فضای آزاد در دنیای خودروهای خودران بسیار مشهور است. با این حال ، بسیاری از مردم هنوز تعجب می کنند که چه کاربردی دارد. من فرصتی برای استفاده از آن نداشتم زیرا پیشرفت ها استفاده از فضای آزاد را در اولویت قرار نمی دهند. اما امیدوارم ایده خوبی در مورد استفاده داشته باشم.
معماری شبیه بخش تقسیم بندی با مشکل تشخیص خط است.
 SegNet
SegNetروش رمزگذار-رمزگشایی مشابه روش U-Net است. رمزگذار به معنای پیچیدگی و ویژگی های یادگیری ، رمزگشایی به معنی بازسازی نقشه ویژگی ها است.
 خلبان خودکار تسلا نرم افزار freespace
خلبان خودکار تسلا نرم افزار freespace نتیجه گیری
 (منبع)
(منبع) فراموش نکنید که your خود را به ما بدهید!




بینایی رایانه ای در تسلا
بینایی رایانه ای در تسلا
وقتی به دنیای بینایی رایانه نگاه می کنیم ، می توانیم یک فاصله واقعی بین دوره های واقعیت و آنلاین مشاهده کنید.
به عنوان مثال ، شما ممکن است در یک دوره آنلاین نحوه اجرای یک شبکه YOLO را بیاموزید ، اما یک مورد استفاده در دنیای واقعی ممکن است 7 شبکه YOLO را در GPU های توزیع شده درخواست کند. و معماری HydraNet این چه عجایبی است؟ ما همه اینها را در Coursera نیاموختیم!
بنابراین امروز ، تصمیم گرفتم ویدیویی را از Andrej Karpathy ، AI Lead در تسلا جدا کنم و آنچه را که در داخل نرم افزار تسلا اتفاق می افتد برای شما توضیح دهم. پیوند ویدیو را در پایان این مقاله به اشتراک می گذارم.
امیدوارم متوجه شوید که هیچ چیز را نمی توانید درک کنید ، حداقل از یک مفهوم سطح بالا. < /p> 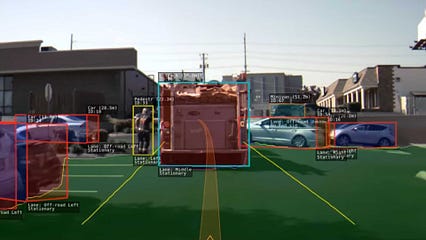
عمیقاً در زیر فرو می رویم:
به طور خاص ، ما به یکی از نگرانی های مهم تسلا می پردازیم: 50 کار باید روی رایانه انجام شود ، به طور همزمان ، در رایانه ای که فضای زیادی را اشغال نمی کند.
 رایانه FSD
رایانه FSD پس بیایید به آن برسیم!
قبل از آن
1. وظایف
به گفته ایلان ماسک ، از ابتدای ژوئیه (2020) ، تسلا به خودروهای کاملاً خودران نزدیک است-که به عنوان خودمختاری سطح 5 نیز شناخته می شود. چه واقعیت داشته باشد چه نباشد ، یک چیز بیش از پیش روشن می شود: تسلا آماده است تا قبل از دیگران به خودمختاری کامل برسد. هنگامی که آنها این کار را انجام می دهند ، بقیه احتمالاً به سرعت دنبال می شوند.
یک وسیله نقلیه تسلا چه کار می کند؟
عملکرد اصلی هر وسیله نقلیه خودران ، از جمله کارهایی که در تسلا انجام می شود این است که در خط صحیح بمانید ، سپس مسیر را تغییر دهید تا مسیر درست را دنبال کنید.
بدیهی است که وظایفی مانند تشخیص موانع بخش بزرگی از پشته است. و ویژگی های دیگر مانند Smart Summon به خودرو اجازه می دهد تا راننده را در یک پارکینگ پیدا کند. این وظایف اضافی ، در میان سایر وظایف ، به خط اصلی و مسیر اصلی حرکت می کند تا به سمت هدف بلند مدت حرکت کند: قابلیت های کامل خودران.
 تسلا باید تمام این وظایف را انجام دهد
تسلا باید تمام این وظایف را انجام دهد 2. حسگرها
تسلا از 8 دوربین برای عملکرد استفاده می کند. با این کار ، آنها می توانند تمام مناطق اطراف وسیله نقلیه را پوشش دهند تا نقطه کوری وجود نداشته باشد.
 نمای از 8 دوربین
نمای از 8 دوربین 8 دوربینبا RADAR های اضافی ترکیب می شوند تا بتوانند موانع را به طور م locateثر شناسایی و آنها را شناسایی کنند. RADAR ها حسگرهای مکمل بسیار خوبی هستند زیرا می توانند سرعتها را مستقیماً تخمین بزنند. می توانید در مقاله RADAR من بیشتر بیاموزید.
این تصاویر دوربین چگونه پردازش می شوند؟ استفاده از شبکه های عصبی.
3. شبکه های عصبی
بین وسایل نقلیه ، خطوط پیاده رو ، حاشیه جاده ها ، گذرگاه ها و سایر متغیرهای محیطی خاص ، تسلا کارهای زیادی برای انجام دادن دارد. در حقیقت ، آنها باید حداقل 50 شبکه عصبی را به طور همزمان اجرا کنند تا بتواند کار کند. این امر در رایانه های معمولی امکان پذیر نیست.
 شبکه عصبی تسلا < /img>
شبکه عصبی تسلا < /img> شبکه های عصبی با استفاده از PyTorch ، یک چارچوب یادگیری عمیق که ممکن است با آن آشنا باشید ، آموزش می بینند.
چیز دیگری که تسلا استفاده می کند نمای چشم پرنده است
گاهی اوقات نتایج یک شبکه عصبی باید به صورت سه بعدی تفسیر شود. نمای چشم پرنده می تواند به تخمین فاصله ها کمک کند و درک بسیار بهتر و واقعی تری از جهان ارائه دهد.
 احضار هوشمند در تسلا با استفاده از نمای چشم پرنده
احضار هوشمند در تسلا با استفاده از نمای چشم پرنده برخی از کارها بر روی چندین دوربین اجرا می شوند. به عنوان مثال ، برآورد عمق چیزی است که ما عموما در دوربین های استریو انجام می دهیم. داشتن 2 دوربین به تخمین بهتر فاصله ها کمک می کند. تسلا این کار را با استفاده از شبکه های عصبی با رگرسیون در عمق انجام می دهد.
 برآورد عمق از 2 دوربین
برآورد عمق از 2 دوربین تسلا همچنین وظایف مکرر مانند برآورد چیدمان جاده دارد. این ایده مشابه است: چندین شبکه عصبی به طور جداگانه اجرا می شوند و یک شبکه عصبی دیگر در حال ایجاد اتصال است.

به صورت اختیاری ، این شبکه عصبی می تواند مکرر باشد تا زمان را در بر گیرد.
به این معنی است که برای هر پاس رو به جلو ، 4096 تصویر پردازش می شود. من در مورد شما اطلاعی ندارم ، اما MacBook Pro من هرگز نمی تواند از این پشتیبانی کند. در واقع ، GPU نمی تواند این کار را انجام دهد - نهحتی 2 GPU!
برای حل این مشکل ، تسلا روی معماری HydraNet شرط بندی می کند. هر دوربینی از طریق یک شبکه عصبی واحد پردازش می شود. سپس همه چیز در شبکه عصبی میانی ترکیب می شود. نکته شگفت انگیز این است که هر کاری تنها به چند قسمت از این شبکه غول پیکر نیاز دارد.
به عنوان مثال ، تشخیص شیء فقط به دوربین جلو ، ستون فقرات جلو و دوربین دوم نیاز دارد. همه چیز یکسان پردازش نمی شود.
 8 شبکه عصبی اصلی مورد استفاده تسلا
8 شبکه عصبی اصلی مورد استفاده تسلا 4. آموزش
آموزش شبکه با استفاده از PyTorch انجام می شود. چندین کار مورد نیاز است و آموزش بر روی 48 سر شبکه عصبی می تواند زمان زیادی را صرف کند. در حقیقت ، آموزش برای تکمیل به 70،000 ساعت GPU نیاز دارد. تقریباً 8 سال است.
تسلا در حال تغییر حالت آموزش از "رفت و برگشت" به "استخر کارگران" است. در اینجا ایده وجود دارد: در سمت چپ - گزینه طولانی و غیرممکن. در وسط و راست ، گزینه های جایگزین مورد استفاده آنها.

5. بررسی کامل پشته
امیدوارم اکنون ایده روشنی از نحوه کار در آنجا داشته باشید. درک آن غیرممکن نیست ، اما قطعاً متفاوت از چیزی است که ممکن است به آن عادت کرده باشیم. چرا؟ از آنجا که این شامل مشکلات بسیار پیچیده ای در دنیای واقعی است.
علاوه بر این ، تسلا باید به طور مداوم نرم افزار خود را بهبود بخشد. آنها باید داده های کاربران را جمع آوری کرده و از آنها استفاده کنند. از این گذشته ، آنها هزاران وسیله نقلیه دارند که در آنجا رانندگی می کنند ، احمقانه خواهد بود که از داده های آنها برای بهبود مدل خود استفاده نکنند. هر داده ای جمع آوری ، برچسب گذاری و برای آموزش استفاده می شود. شبیه فرایندی به نام یادگیری فعال (در این مورد در اینجا اطلاعات بیشتری کسب کنید).
 پشته کامل تسلا
پشته کامل تسلا بیایید پشته را از پایین به بالا تعریف کنیم.
⏩ در اینجا ویدئویی است که همه چیز را شرح می دهد. فقط تصاویری را که به شما نشان دادم نوشتم و جمع آوری کردم.
ممکن است کمی از همه چیز که توضیح دادم غرق شده باشید. بسیار پیشرفته تر از آن چیزی است که اکثر دوره ها آموزش می دهند ، و طبیعی است. با این حال ، امروزه شرکت ها اینگونه عمل می کنند. آن استبه ندرت می توان شرکتی را مشاهده کرد که از دسته های از پیش ساخته شده از لایه های متحرک بدون تغییر استفاده کند.
در اینجا خلاصه ای از همه مواردی است که ما در مورد آن بحث کردیم:
هدف تسلا این است که اولین شرکتی باشد که به خودمختاری کامل دست یافته است. امروزه آنها با ارزش ترین شرکت خودروسازی در کل جهان هستند و قصد توقف در آنجا را ندارند. آنها با چالش های جالبی روبرو هستند که ما در هنگام یادگیری هوش مصنوعی و یادگیری عمیق از راحتی خانه های خود با آنها روبرو نیستیم.
تبصره ویرایشگر: ضربان قلب یک نشریه و انجمن آنلاین مبتنی بر مشارکت است که به کاوش در تقاطع نوظهور توسعه برنامه تلفن همراه و یادگیری ماشین اختصاص داده شده است. ما متعهد هستیم که از توسعه دهندگان و مهندسان از هر قشری حمایت و الهام بگیریم.
مستقل از نظر ویرایش ، Heartbeat توسط Fritz AI ، پلت فرم یادگیری ماشینی که به توسعه دهندگان کمک می کند تا دستگاه ها را ببینند ، بشنوند ، حمایت و منتشر می شود. حس کنید و فکر کنید ما به مشارکت کنندگان خود پرداخت می کنیم و تبلیغات نمی فروشیم.
اگر می خواهید مشارکت داشته باشید ، به تماس ما برای مشارکت کنندگان سر بزنید. همچنین می توانید برای دریافت خبرنامه های هفتگی ما (هفته نامه یادگیری عمیق و خبرنامه هوش مصنوعی Fritz) ثبت نام کنید ، در Slack به ما بپیوندید و Fritz AI را در توییتر دنبال کنید تا آخرین یادگیری ماشین تلفن همراه را مشاهده کنید.
تجربه من با استفاده از برنامه های کارشناسی ارشد علوم کامپیوتر بدون سابقه
تجربه من با استفاده از برنامه های کارشناسی ارشد علوم کامپیوتر بدون سابقه
[چرا تصمیم گرفتم به مقطع دبیرستان بروم]
به طور کلی نحوه علاقه مندی خود را ارائه کردم در مطالعه علوم کامپیوتر در پست قبلی وبلاگم. این همه عالی است ، اما همه هنگام انتخاب حرفه ای در علوم کامپیوتر ، مسیر دانشگاه را انتخاب نمی کنند. اما در اینجا دلایل من برای اینکه چرا من به دنبال آموزش رسمی هستم آمده است:
به هر حال ، من نویسنده بزرگی نیستم ، اما احساس کردم همانطور که در حین آماده شدن برای درخواست برنامه کارشناسی ارشد در علوم کامپیوتر ، نمی توانم به منابع بسیار زیادی مراجعه کنم. بنابراین در اینجا تلاش صادقانه من برای به اشتراک گذاشتن تجربه کامل من است. امیدوارم کمک کند.
 با من تحمل کنید
با من تحمل کنید 0 پیشینه علمی صادقانه من
بی شرمانه اعتراف می کنم که لیست مدارس بالقوه خود را بر اساس لیست های ارائه شده توسط این رتبه بندی ها انتخاب کرده ام:

بودن راستش ، من نمی دانستم چگونه فهرستی از مدارس تهیه کنم و برای من ، این مکان عالی برای شروع بود.
2. فیلتر کردن لیست مدارس
در اینجا مواردی است که من هنگام مشاهده برنامه های مختلف به آنها توجه کردم: لیسانس در علوم کامپیوتر یا دانش آموزان پذیرفته شده با مدرک کارشناسی در زمینه کمی مانند مهندسی ، ریاضی ، فیزیک و غیره در س theالات متداول یا بخش دانشجویان آینده نگر.
3. تصمیم گیری در مورد کلاسها
در نهایت یک صفحه گسترده با نام مدرسه ، محل تحصیل ، شهریه ، مهلت درخواست و دوره های پیش نیاز ایجاد کردم. من همچنین باید هنگام تهیه لیست پیش نیازها مراقب باشم زیرا برخی از پیش نیازها پیش نیازهای خاص خود را داشتند. SIGH.
من کاملاً مطمئن نیستم که میزان پذیرش در چه نوع/تعداد کلاس های CS/ریاضی شرکت کرده است. من فقط لیستی از دوره ها را بر اساس همپوشانی تهیه کردم و می دانستم که باید خوب کار کنم. به هر حال ، در اینجا لیستی از کلاسها و نمرات من آمده است: الف)
فقط یک FYI ، برنامه های پس از مدرک کارشناسی/برنامه های گواهینامه حرفه ای وجود دارد که می تواند شما را برای مدارس مقطع دبیرستان و مراحل حرفه ای آماده کند. برای نام بردن چند مورد: NYU ، Columbia ، Tufts ، BU ، و غیره ... (مطمئنم تعداد بیشتری وجود دارد).
4. آماده شدن برای GRE
من کتاب آمادگی GRE Barron را خریدم و همچنین برای یک برنامه 3 ماهه Magoosh (*زمانی که در فروش بود*) ثبت نام کردم. من فکر می کردم هر دو منبع از نظر تمرین زیاد بسیار عالی هستند.
من نمی توانم با اطمینان بگویم که هنگام آماده شدن برای GRE خود انضباط زیادی داشتم. من تقریباً یک ماه قبل از امتحانم به طور جدی درس خواندم ، که احتمالاً بهترین نبود. با این حال ، من دائماً در حال جستجوی کارت های واژگانی بودم که از طریق Magoosh به صورت رایگان در فروشگاه برنامه شما موجود است. واقعا مهم است من بیشتر روی بخش کمی تمرکز کردم اما برای مدتی که گذاشتم ، باور ندارم که در تاریخ آزمون خیلی خوب عمل کرده ام.
اما همانطور که مردم می گفتند ، GRE برای مواد مخدر SAT بود و من امیدوارم دیگر مجبور نباشم خود را در این زمینه تحمل کنم ...
 دوباره ، HARD PASS.
دوباره ، HARD PASS. 5. نوشتن بیانیه هدف
همانطور که در بالا اشاره کردم ، از مهارت های نوشتاری خود اطمینان چندانی ندارم.
 یادداشت جانبی: من کاملاً مطمئن هستم که من از کلاس زبان انگلیسی کلاس 10 خود PTSD دارم زیرا معلم من هرگز از ذکر این نکته که خطاهای من همه مربوط به ESL است (اما برای ضبط کنید ، من همیشه در تمام کلاسهای انگلیسی خود بسیار خوب کار کرده ام) !!
یادداشت جانبی: من کاملاً مطمئن هستم که من از کلاس زبان انگلیسی کلاس 10 خود PTSD دارم زیرا معلم من هرگز از ذکر این نکته که خطاهای من همه مربوط به ESL است (اما برای ضبط کنید ، من همیشه در تمام کلاسهای انگلیسی خود بسیار خوب کار کرده ام) !! من بیانیه هدف خود را آنقدر بار دیگر اصلاح کردم که حتی نمی توانم حساب کنم. همچنین ، در ابتدا من تفاوت بین یک اظهارنظر شخصی و یک اظهارنظر را نمی دانستم. وقتی فهمیدم ، آن را خراب کردم.
من در ابتدا سخت تلاش کردم تا همه چیزهایی را که از دوران دانشجویی آموخته ام/تجربه کرده ام به دلیل درخواستم برای برنامه های تحصیلات تکمیلی علوم کامپیوتر متصل کنم.
به عنوان مثال ، من مجبور بودم به نحوی توضیح دهم که چگونه سابقه زیست شناسی ، مطالعات بین المللی و تحقیقات بالینی مرا به خوبی برای دانشگاه ها آماده کرده استعلوم کامپیوتر. این کار بسیار به فکر (در مورد دیگران مطمئن نیستم اما باز هم ، این تجربه من است) و تلاش زیادی بود. اما سرانجام ، با کمک دیگران ، من توانستم طوفان فکری زیادی در زمینه های مختلف داشته باشم!
مطمئنم که این مطلب را در بسیاری از پست ها در رابطه با درخواست برای مدارس مقطع دکتری خواهید خواند ، اما مطمئن شوید که در مورد برنامه (اعم از استاد ، کلاس یا جنبه ای از برنامه که واقعاً به آن علاقه دارید) تحقیق کنید و در مورد اینکه چگونه می تواند برای شما مفید باشد صحبت کنید.
من همچنین از ویرایش جسیکا یون بسیار سود بردم. خدمات. خدمات او بیش از حد عالی بود و او در هنگام نوشتن SOP به من اعتماد به نفس داد. او بسیار واجد شرایط است - اما مهمتر از همه ، او از راه دور و سریع با شما کار خواهد کرد.
بنابراین ، به طور خلاصه هر توصیه ای که از تجربه شخصی من حاصل شده است:
6. فرآیند درخواست اگر می توانم روی یک چیز تأکید کنم: *مطمئن شوید که توصیه های خود را پیشاپیش خوب نوشته اید *.
با اساتید خود تماس بگیرید (مهم این است که اکثریت از اساتید CS هستند) که فکر می کنید شما را بیشتر می شناسند در محیط دانشگاهی اگر به درستی به خاطر دارم ، سه ماه قبل از اساتیدم (همه اساتید از کلاسهای پیش نیازم تا بتوانند مرا بخاطر بسپارند) خواستم و حداکثر یک هفته قبل پیوندهای توصیه ای را برای آنها ارسال کردم.
در واقع ممکن است یک هفته آن را تحت فشار قرار دهد (من می گویم که دو مورد در امن هستند) اما یکی از مواردی که برای برخی از مدارس متوجه نشدم این است که شما باید بخشی از فرایند درخواست خود را به پایان برسانید تا سیستم ارسال شود پیوندهای توصیه به اساتید !! پس آگاه باشید!
 آیا شما جدی
آیا شما جدی اگر من می تواند خلاصه شود:
7. تصمیمات
در اصل ، من فقط در دو برنامه شرکت کردم. اما در پایان ، من واقعاً فکر نمی کردم که قرار است به جایی بروم ، بنابراین خوشحال بودم که حداقل به جایی رسیدم. من حتی رقص شاد را انجام دادم.

بدیهی است ، برنامه هایی که من وارد آن نشدم رتبه بالاتری داشتند اما هنوز نمی دانمدلایلی که باعث شد در برخی برنامه ها شرکت کنم و برای برخی دیگر این کار را نکردم. من می توانم یک میلیون دلیل برای اینکه مانند تجربه ناکافی ، معدل متوسط ، SOP متوسط ، و لیست ادامه دارد ، حدس بزنم ، اما هرگز نمی دانم. من سعی کردم در مراحل برنامه به GradCafe مراجعه کنم اما احساس نمی کردم که اینقدر آموزنده باشد.
 EH
EH به هر حال ، من تصمیم گرفتم NYU را در مورد هاپکینز انتخاب کنم زیرا معتقد بودم که در شهر نیویورک فرصت های فناوری بهتر یا بیشتر برایم فراهم می شود و من واقعاً از این واقعیت که برنامه در مقابل 1.5 سال هاپکینز ، 2 سال کامل بود. مشخصات جمعیتی هر دو مدرسه تقریباً مشابه بود و حتی اگر میزان اشتغال پس از فارغ التحصیلی برای من بسیار مهم بود ، این اطلاعات از آنها در دسترس نبود ... (و من هنوز مطمئن نیستم چرا).
پف ، متأسفم برای پست طولانی اما امیدوارم تا حدودی مفید /آموزنده بوده باشد. من می دانم که این بسیار طاقت فرسا است و ممکن است این فرآیند دلهره آور به نظر برسد ، اما اگر من بتوانم این کار را انجام دهم ، شما نیز می توانید! اگر س questionsالی دارید ، لطفاً در زیر نظر دهید و منتظر بازخورد هستم :)
allthegifswereprovidedbygiphy.com
من مهندسی برق و کامپیوتر می خوانم. به من C ، C ++ و جاوا از طریق دوره های دانشگاهی آموزش داده شده است.
من مهندسی برق و کامپیوتر می خوانم. به من C ، C ++ و جاوا از طریق دوره های دانشگاهی آموزش داده شده است.
تا تابستان گذشته هیچگونه لینوکس یا اطلاعات infosec نداشتم. من با یادگیری پایتون با کتاب "پایتون را از راه سخت بیاموزید" را شروع کردم.
سپس به مطالعه کتابهای تخصصی تر پرداختم ، در حالی که منابع آنلاین را مرور می کردم و چیزهایی را که با بازی های جنگی یاد می گرفتم تمرین می کردم مانند http: //overthewire.org
خواندن پیشنهادی: